Demystifying Stripe Width in vSAN
In traditional SAN, to drive optimal performance, many vendors deploy a concept of wide striping across many hard drives within the storage sub system. Assuming that a typical 10k RPM SAS drives can produces ~150 IOPS per drive, simply having your data now spread across 10 similar drives would produce ~1,500 IOPS.
This made a lot of sense when you had monolithic storage sub systems that span a couple of thousand drives. Some even built their claims over a bunch of SATA drives outperforming FC / SAS storage systems just on the concept of wide striping. The only caveat though as you may have guessed, there is a need to deploy a minimum set of fully populated drives / drive enclosures. Otherwise, no collective performance.
Armed with that knowledge of wide striping, many vSAN administrators often go about troubleshooting vSAN performance simply by adding additional stripe widths (which is equivalent to wide striping in traditional SAN), hoping to improve performance. Depending on the cause of the bottleneck, often times, there isn’t any noticeable improvements after increasing the stripe width. Hmmm…
Before I go in depth demystifying stripe widths, to set the context, unlike traditional SAN where you could potentially span / stripe across a thousand drives, the maximum stripe width in vSAN is 12. It may not seem like much, but I'll get to that in a bit. Like everything in vSAN, stripe width is driven from a policy and that simply means the flexibility to have this applied at the granularity of a VMDK or VM unlike traditional SAN.
How does it work?

In the example above, a typical FTT=1, Raid 1 with stripe width (SW) = 2, would have each mirrored copy data spread across 2 x HDD’s on the capacity tier. This simply means, in the scenario above, you could have up to 4 spindles working for you at any point in time if required. Assuming you set SW=12, in a similar policy above, you would have 24 HDD’s.
The placement of data is determined by vSAN and this could be different drives within the same disk group (stripe-1a & stripe-1b) or across multiple disk groups (stripe-2a & stripe-2b), and FTT rules are still honored.
So why does stripe width NOT improve performance?
For this, we need to revisit the IO Flow (diagram below) for vSAN to fully understand it. In a hybrid vSAN, the flash tier is used for caching reads and writes while the HDD are used as capacity. Sizing is often done in a way that 90% of the read IO's would be served at the flash cache tiers. The remainder of the 10%, we call "read cache miss" would then need to be retrieved from the slower HDD tier. Writes are simpler, IO is complete when it gets acknowledged at the flash tier. Using an elevator algorithm, it will then be destaged to the HDD tier as the write buffer fills.
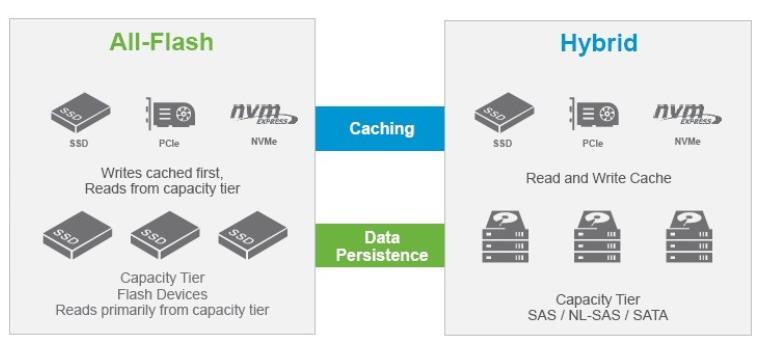
Coming back to stripe width, when applied, the policy only impacts data that is persistent on the HDD capacity tier. Based on the IO flow of a hybrid vSAN, read performance improvements will likely only impact "read cache misses" which equates to 10% or less of your total read IO's.
As for writes, commits are done at the flash tiers. So, stripe width have little bearing on writes, but I will come back to this later.
Assuming the placement of data is across 2 disk groups, there is a small chance that performance may improve for both reads and writes because data is now cached on 2 flash devices, instead of 1, but there is really no way to predict this.
How does stripe width drive better performance then?
It is highly dependent on the workload we are trying to address. Assuming you had a workload that is extremely high on random read and is consistently missing cache, increasing stripe width will definitely improve, given that the HDD's tiers will be carrying the bulk of the IO's.
Another scenario could be an extremely aggressive write workload. As mentioned earlier, when the write buffers fill, vSAN starts destaging a little more aggressively to the HDD tiers. Given the speed gap between flash and HDD, destaging performance may be a bottle necked at the HDD causing back pressure. Increasing stripe width on the HDD capacity tier will increase destaging performance. However, this back pressure scenario is rare.
So what is the recommendation for implementing stripe width?
It is probably best to start with the default stripe width of 1. We have had many customers without issues with the defaults. If there is a need to tweak performance (important yo understand the characteristics of the workload), increase it to 2 or 3, and monitor accordingly. You will probably notice that rarely anything beyond a stripe width of 3 will yield significant performance improvements.
Hope this helps.