VxRail P570F Performance Benchmark
Thanks to our friends at Dell EMC, we had 4 x VxRail P570F’s in the office recently. The P-series are classed under the Performance Range of boxes and its often time what is proposed for demanding workloads (refer to datasheet excerpt below). Again, the performance of any system (regardless of classifications) are highly dependent on the configuration that it is built on.
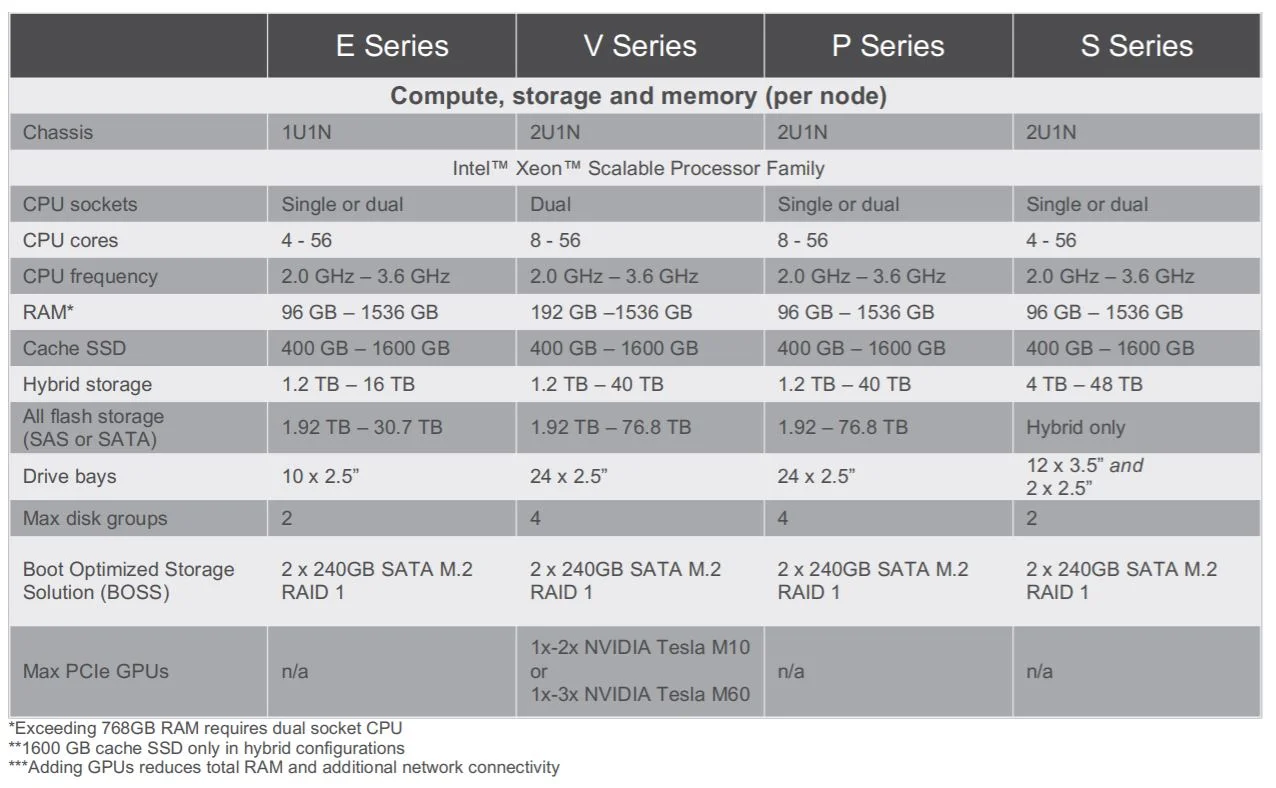
The units that we had were of the following configs. The config below is per node.

2 x Intel Xeon Gold 6130 2.1GhZ
384 GB DDR4 2666 RAM
2 x 800GB Write Intensive SAS SSD
10 x 3.84TB Read Intensive SAS SSD
1 x HBA330 Controller
It was a fairly standard / generic DEMO system and not remotely a maxed out P-Series configuration. There is still a lot of room to grow in terms of additional cache drives and capacity drives. Think of this as a baseline of roughly what you could get.
The benchmark tests were done using a synthetic load generator, HCIBench. While it is part of the VMware Fling site download, it is in no way tweaked to make vSAN look good (I promise!). I have used IOMeter as well, and results were similar. The underlying load gen of HCIBench is of the popular VDBench and all VMware have done is put a nice looking GUI on top of it and automation to make deploying VDBench faster / easier.
The tests were also done with generic out-of-the-box configurations with ZERO tweaking. The workload profile tested is a typical 70% Read 30% Write on 8k Blocks, which is common in most Enterprises. I have also used RAID 5 Erasure Coding to introduce additional overheads to simulate worst case scenarios. Would have liked to do RAID 6 but I have insufficient nodes for it. The tests were then done against multiple Outstanding IO (OIO) variables. The definition of OIO’s are IO’s waiting in queue. More OIO’s usually results in higher IOPS and potentially an increase in latency. The sweet spot for OIO’s is often the cross-over point where additional OIO’s generates marginal IOPS improvements and significant latency increase.

The results of the benchmark runs
The diagram above shows that latency is significantly amplified beyond OIO=48. Like mentioned earlier, this is the sweet spot for this config. Can you run it at higher OIO and workloads? Sure! The increment may be marginal beyond that, but if the IOPS & Latency is still within the thresholds that is comfortable to your applications / users. No issues at all.
Having said that, for a small cluster running such a workload at 160,000 IOPS; 70/30; 8K block; <2ms Read Latency and <5ms Write Latency, this would be more than sufficient for most Enterprise applications (historically, for traditional SAN’s, anything <20ms is a good day).
Of course, the beauty of vSAN have always been it’s ability to apply specific policies at the granularity of a VM/VMDK. So if there are specific applications that require better performance/lower latency, a RAID 1 policy can be applied, while others remained at RAID 5.
Hopefully, the numbers above gives you a sample of what you can roughly expect from a typical Enterprise workload profile on a system with the above config, and not some HERO number of 100% Reads (which I hope you guys realise its unrealistic).